This post describes how I exported my 500+ YouTube subscriptions to an OPML file so that I could import them into my RSS reader. I go into fine detail about the scripts and tools I used. If you just want to see the end result the code is in this repository, which describes the steps needed to run it.
I was previously a YouTube Premium subscriber but I cancelled it when they jacked up the already high prices. Since then I’ve been watching videos in NewPipe on my Android tablet or via an Invidious instance on real computers.
To import my subscriptions into NewPipe I was able to use the
subscriptions.csv file included in the Google Takeout dump of my YouTube
data. This worked fine initially but imposed some friction when adding new
subscriptions.
If I only subscribed to new channels in NewPipe they were only accessible on my tablet. If I added them to YouTube then I had to remember to also add them in NewPipe, which was inconvenient if I wasn’t using the tablet at the time. Inevitably the subscriptions would drift out of sync and I would have to periodically re-import the subscriptions from YouTube into NewPipe. This was cumbersome as it doesn’t seem to have a way to do this incrementally. Last time I had to nuke all its data in order to re-import.
To solve these problems I wanted to manage my subscriptions in my RSS reader, Feedbin. This way Feedbin would track my subscriptions and new/viewed videos in a way that would sync between all my devices. Notably this is possible because Google actually publishes an RSS feed for each YouTube channel.
To do that I needed to export all my subscriptions to an OPML file that Feedbin
could import. I opted to do that without requesting another Google Takeout dump
as they take a long time to generate and also result in multiple gigabytes of
archives I have to download (it includes all the videos I’ve uploaded to my
personal account) just to get at the subscriptions.csv file within.
Generating OPML
I started by visiting my subscriptions page and using some JavaScript to generate a JSON array of all the channels I am subscribed to:
copy(JSON.stringify(Array.from(new Set(Array.prototype.map.call(document.querySelectorAll('a.channel-link'), (link) => link.href))).filter((x) => !x.includes('/channel/')), null, 2))
This snippet:
- queries the page for all channel links
- gets the link URL of each matching element
- Creates a
Setfrom them to de-duplicate them - Turns the set back into an
Array - filters out ones that contain
/channel/to exclude some links like Trending that also appear on that page - Turns the Array into pretty printed JSON
- Copies it to the clipboard
With the list of channel URLs on my clipboard I pasted this into a
subscriptions.json file. The challenge now was that these URLs were of the
channel pages like:
https://www.youtube.com/@mooretech
but the RSS URL of a channel is like:
https://www.youtube.com/feeds/videos.xml?channel_id=<CHANNEL_ID>,
which means I needed to determine the channel id for each page. To do that without futzing around with Google API keys and APIs I needed to download the HTML of each channel page.
First I generated a config file for curl from the JSON file:
jaq --raw-output '.[] | (split("/") | last) as $name | "url \(.)\noutput \($name).html"' subscriptions.json > subscriptions.curl
jaq is an alternative implementation of jq that I use. This jaq expression does the following:
.[]iterate over each element of thesubscriptions.jsonarray.(split("/") | last) as $$namesplit the URL on/and take the last element, storing it in a variable called$name.- for a URL like
https://www.youtube.com/@mooretechthis stores@mooretechin$name.
- for a URL like
"url \(.)\noutput \($$name).html"generates the output text interpolating the channel page url and channel name.
This results in lines like this for each entry in subscriptions.json, output
to subscriptions.curl:
url https://www.youtube.com/@mooretech
output @mooretech.html
I then ran curl against this file to download all the pages:
curl --location --output-dir html --create-dirs --rate 1/s --config subscriptions.curl
--locationtells curl to follow redirects, for some reason three of my subscriptions redirected to alternate names when accessed.--output-dirtells curl to output the files into thehtmldirectory.--create-dirstells curl to create output directories if they don’t exist (just thehtmlone in this case).--rate 1/stells curl to only download at a rate of 1 page per second—I was concerned YouTube might block me if I requested the pages too quickly.--config subscriptions.curltells curl to read additional command line arguments from thesubscriptions.curlfile generated above.
Now that I had the HTML for each channel I needed to extract the channel id
from it. While I was processing each HTML file I also extracted the channel
title for use later. For each HTML file I ran this script on it. I called the
script generate-json-opml:
#!/bin/sh
set -eu
URL="$1"
NAME=$(echo "$URL" | awk -F / '{ print $NF }')
HTML="html/${NAME}.html"
CHANNEL_ID=$(scraper -a content 'meta[property="og:url"]' < "$HTML" | awk -F / '{ print $NF }')
TITLE=$(scraper -a content 'meta[property="og:title"]' < "$HTML")
XML_URL="https://www.youtube.com/feeds/videos.xml?channel_id=${CHANNEL_ID}"
json_escape() {
echo "$1" | jaq --raw-input .
}
JSON_TITLE=$(json_escape "$TITLE")
JSON_XML_URL=$(json_escape "$XML_URL")
JSON_URL=$(json_escape "$URL")
printf '{"title": %s, "xmlUrl": %s, "htmlUrl": %s}\n' "$JSON_TITLE" "$JSON_XML_URL" "$JSON_URL" > json/"$NAME".json
Let’s break that down:
- The channel URL is stored in
URL. - The channel name is determined by using
awkto split the URL on/and take the last element. - The path to the downloaded HTML page is stored in
HTML. - The channel id is determined by finding the
<meta>tag in the html with apropertyattribute ofog:url(the OpenGraph metadata URL property). This URL is again split on/and the last element stored inCHANNEL_ID.- Querying the HTML is done with a tool called scraper that allows you to use CSS selectors to extract parts of a HTML document.
- The channel title is done similarly by extracting the value of the
og:titlemetadata. - The URL of the RSS feed for the channel is stored in
XML_URLusingCHANNEL_ID. - A function to escape strings destined for JSON is defined. This makes use of
jaq. TITLE,XML_URL, andURLare escaped.- Finally we generate a JSON object with the title, URL, and RSS URL and write it into a
jsondirectory under the name of the channel.
Update: Stephen pointed out on Mastodon that the HTML contains the usual
<link rel="alternate" tag for RSS auto-discovery. I did check for that initially but
I think the Firefox dev tools where having a bad time with the large size of the YouTube
pages and didn’t show me any matches at the time. Anyway, that could have been used to
find the feed URL directly instead of building it from the og:url.
Ok, almost there. That script had to be run for each of the channel URLs. First I generated a file with just a plain text list of the channel URLs:
jaq --raw-output '.[]' subscriptions.json > subscriptions.txt
Then I used xargs to process them in parallel:
xargs -n1 --max-procs=$(nproc) --arg-file subscriptions.txt --verbose ./generate-json-opml
This does the following:
-n1read one line fromsubscriptions.txtto be passed as the argument togenerate-json-opml.--max-procs=$(nproc)run up the number of cores my machine has in parallel.--arg-file subscriptions.txtread arguments forgenerate-json-opmlfromsubscriptions.txt.--verboseshow the commands being run../generate-json-opmlthe command to run (this is the script above).
Finally all those JSON files need to be turned into an OPML file. For this I used Python:
#!/usr/bin/env python
import email.utils
import glob
import json
import xml.etree.ElementTree as ET
opml = ET.Element("opml")
head = ET.SubElement(opml, "head")
title = ET.SubElement(head, "title")
title.text = "YouTube Subscriptions"
dateCreated = ET.SubElement(head, "dateCreated")
dateCreated.text = email.utils.formatdate(timeval=None, localtime=True)
body = ET.SubElement(opml, "body")
youtube = ET.SubElement(body, "outline", {"title": "YouTube", "text": "YouTube"})
for path in glob.glob("json/*.json"):
with open(path) as f:
info = json.load(f)
ET.SubElement(youtube, "outline", info, type="rss", text=info["title"])
ET.indent(opml)
print(ET.tostring(opml, encoding="unicode", xml_declaration=True))
This generates an OPML file (which is XML) using the ElementTree library. The OPML file has this structure:
<?xml version='1.0' encoding='utf-8'?>
<opml>
<head>
<title>YouTube Subscriptions</title>
<dateCreated>Sun, 05 May 2024 15:57:23 +1000</dateCreated>
</head>
<body>
<outline title="YouTube" text="YouTube">
<outline title="MooreTech" xmlUrl="https://www.youtube.com/feeds/videos.xml?channel_id=UCLi0H57HGGpAdCkVOb_ykVg" htmlUrl="https://www.youtube.com/@mooretech" type="rss" text="MooreTech" />
</outline>
</body>
</opml>
It does the following:
- Generates the top level OPML structure.
- For each JSON file, read and parse the JSON and then use that to generate an
outlineentry for that channel. - Indent the OPML document.
- Write it to stdout using a Unicode encoding with an XML declaration (
<?xml version='1.0' encoding='utf-8'?>).
Whew that was a lot! With the OPML file generated I was finally able to import all my subscriptions into Feedbin.
All the code is available in this
repository. In practice I used a
Makefile to run the various commands so that I didn’t have to remember them.
Watching videos from Feedbin
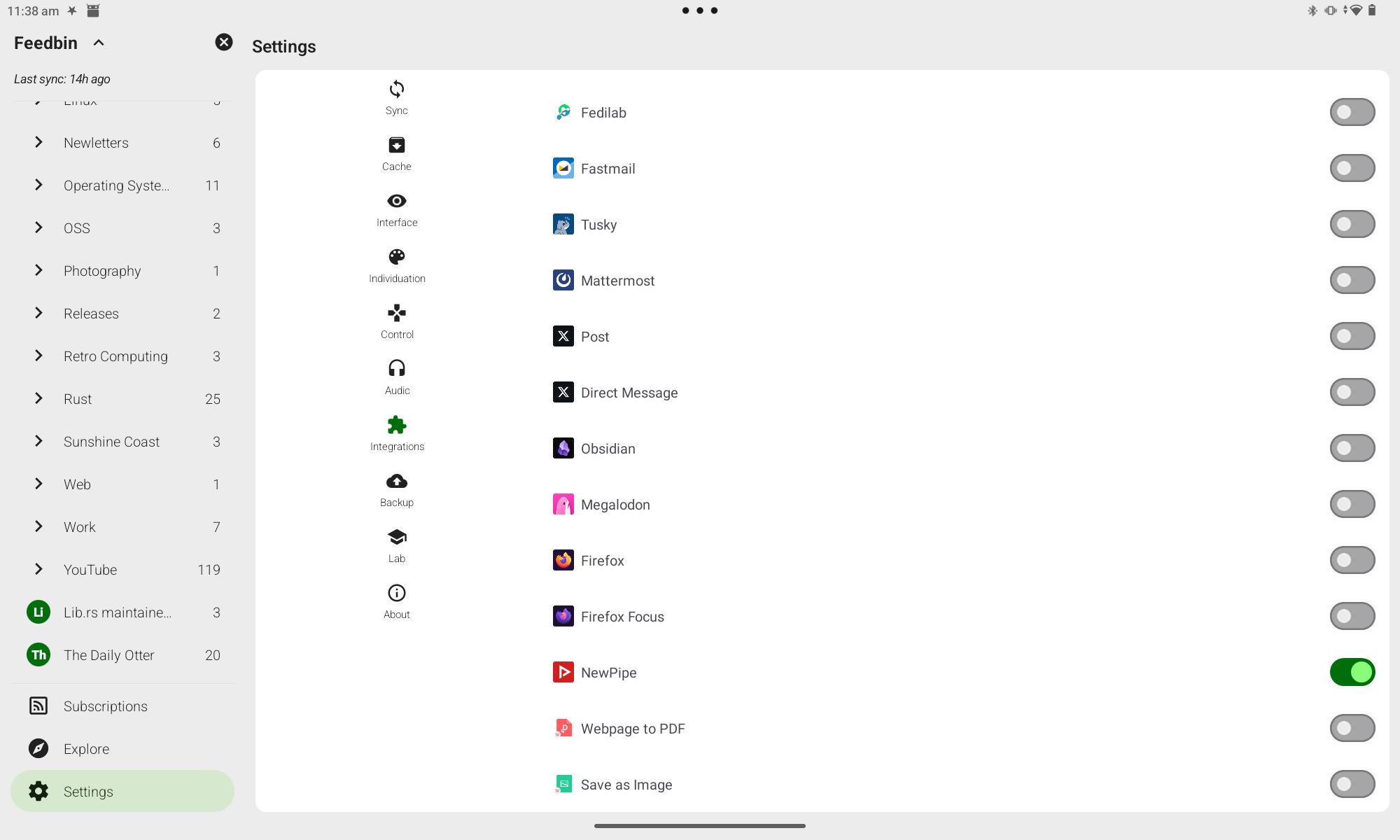
Now that Feedbin is the source of truth for subscriptions, how do I actually watch them? I set up the FeedMe app on my Android tablet. In the settings I enabled the NewPipe integration and set it to open the video page when tapped:
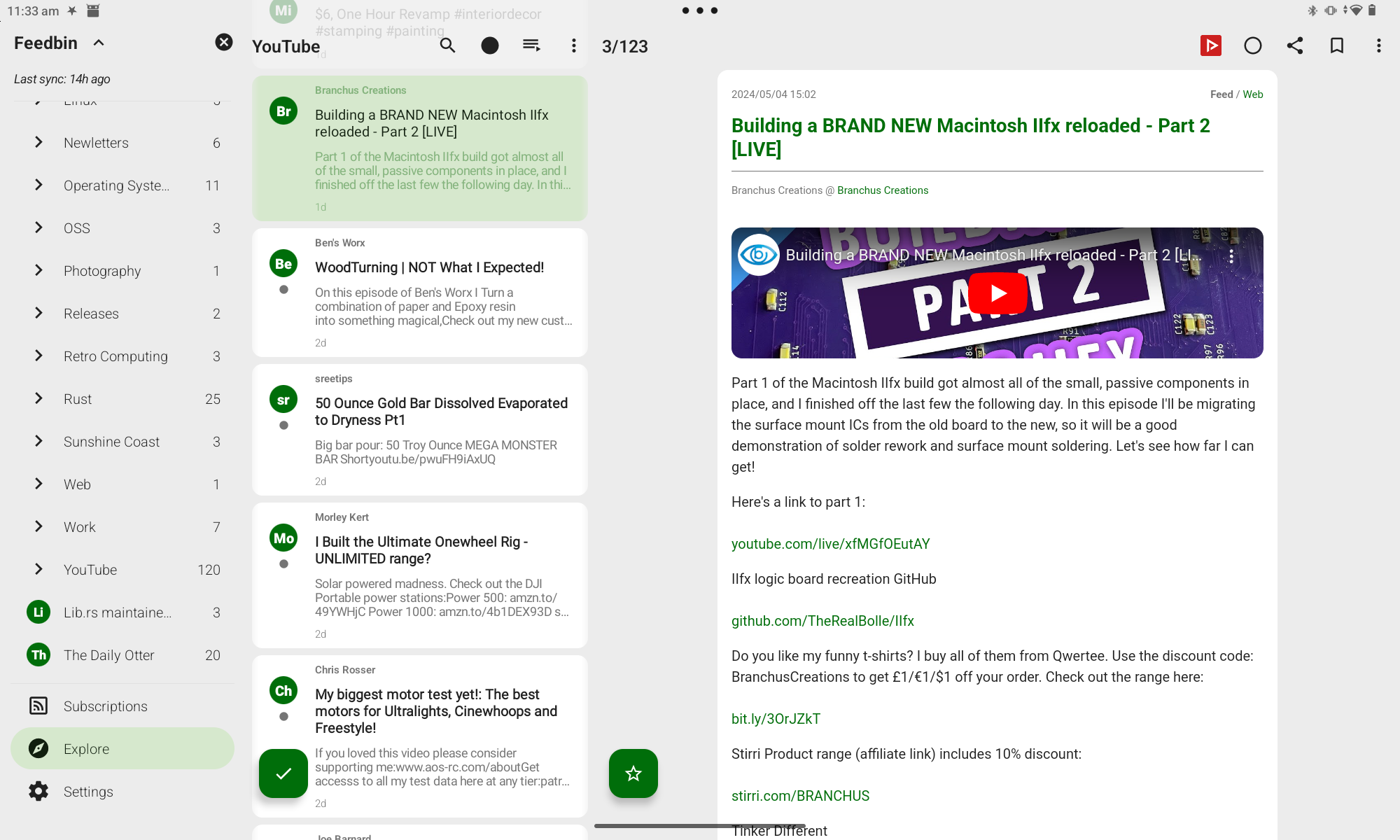
Now when viewing an item in FeedMe there is a NewPipe button that I can tap to watch it:
Closing Thoughts & Future Work
Could I have done all the processing to generate the OPML file with a single Python file? Yes, but I rarely write Python so I preferred to just cobble things together from tools I already knew.
Should I ever become a YouTube Premium subscriber again I can continue to use this workflow and watch the videos from the YouTube embeds that Feedbin generates, or open the item in the YouTube app instead of NewPipe.
At some point I’d like to work out how to get Feedbin to filter out YouTube Shorts. It has the ability to automatically filter items matching any of the supported search syntax but I’m not sure if Shorts are easily identifiable.
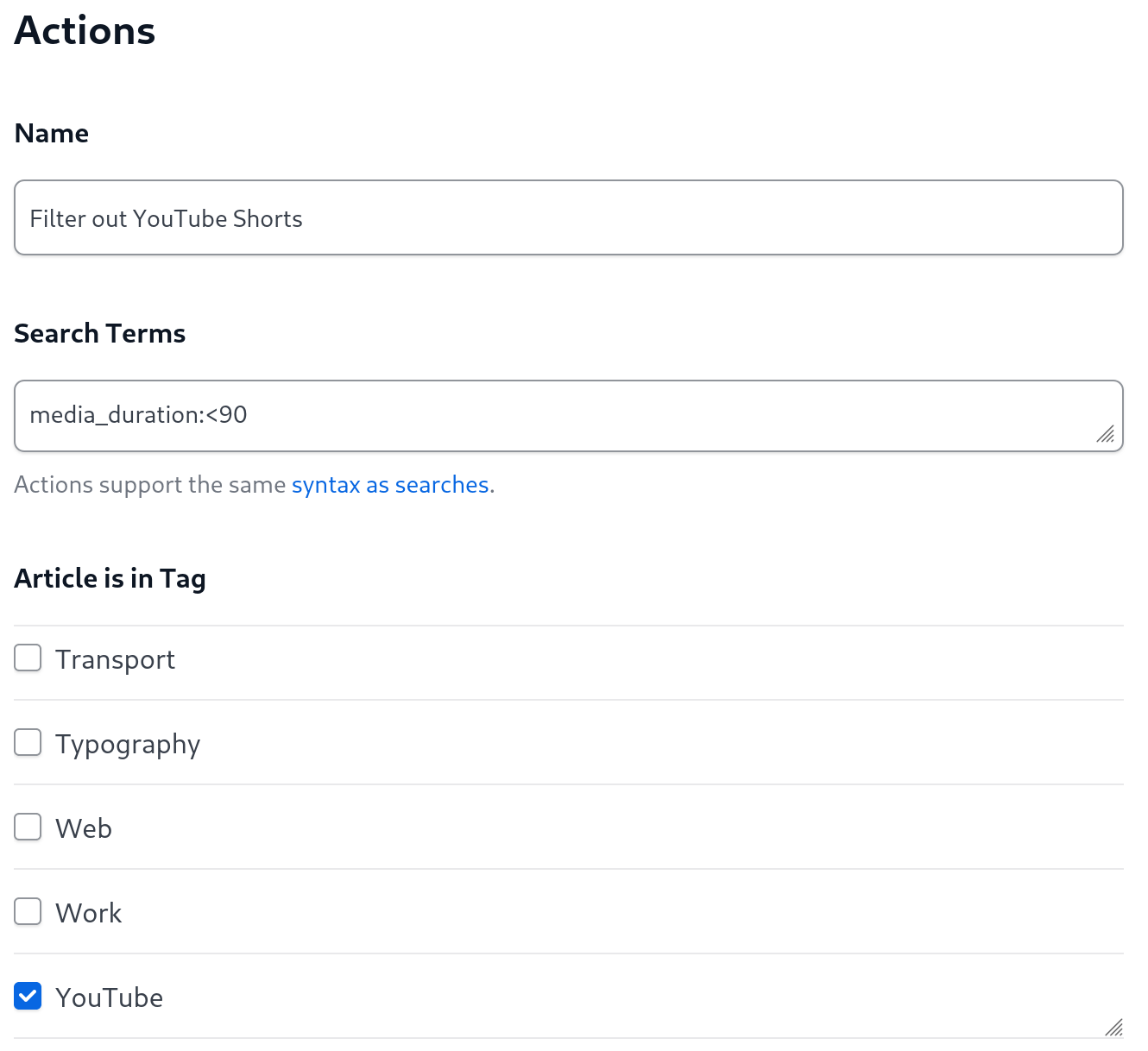
Update 6 June 2024: Feedbin has a media_duration search term. I was able
to use that in an action to filter out YouTube items less than 90 seconds long,
successfully filtering out Shorts.
Lastly, what about desktop usage? When I’m on a real computer I read my RSS via the Feedbin web app. It supports custom sharing integrations. In order to open a video on an Invidious instance I need to rewrite it from a URL like:
https://www.youtube.com/watch?v=u1wfCnRINkE
to one like:
https://invidious.perennialte.ch/watch?v=u1wfCnRINkE.
I can’t do that directly with a Feedbin custom sharing service definition but it would be trivial to set up a little redirector application to do it. I even published a video on building a very similar thing last year. Alternatively I could install a redirector browser plugin, although that would require set up on each of the computers and OS installs I use so I prefer the former option.